
Introduction#
Large Language Models (LLMs) have recently demonstrated remarkable success across a broad range of domains, significantly influencing various aspects of daily life. From code generation to resolving everyday queries, LLMs have transformed how individuals interact with technology. As machine learning systems become increasingly integrated into diverse real-world applications, they are being employed to address a wide variety of domain-specific tasks. This growing complexity necessitates the development of specialized evaluation metrics tailored to each task. However, designing such metrics is often labor-intensive and, in some cases, infeasible using a limited set of deterministic functions.
Certain tasks inherently require subjective assessment, where human judgment plays a critical role in evaluating outcomes. Given that LLMs are trained on extensive and diverse datasets that capture human preferences and reasoning patterns, they can serve as effective evaluators in contexts where traditional rule-based evaluation falls short. Leveraging LLMs as evaluators offers a scalable and consistent alternative to human-in-the-loop assessments for tasks that defy simple, objective measurement.
In this blog, we will explore some popular research themes that exist within this field and examine a few representative examples to gain a broad understanding of the types of work currently being undertaken in this field.
Using LLM for Evaluation#
One of the most prominent use cases for large language models (LLMs) is the evaluation of outputs generated by other models, or more broadly, by various machine learning systems. Notable approaches that formalized this methodology include GPTScore and G-Eval, which differ in their scoring mechanisms.
GPTScore computes the log-probabilities of generating an output sequence given a specific context, question, or task instruction. It essentially sums the token-level log-probabilities of the generated answer conditioned on the preceding context, where h denotes the output and d, a, and S represent components of the context.
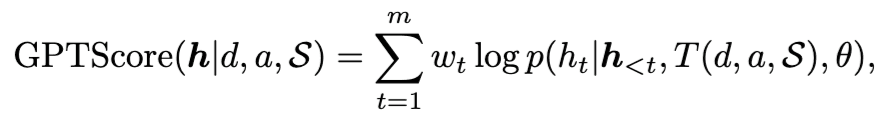
In contrast, G-Eval leverages chain-of-thought (CoT) prompting to guide GPT-4 in articulating its reasoning before producing a final evaluation. This framework frames the evaluation as a structured form-filling task, in which GPT-4 provides both numerical scores and justifications across predefined criteria.
Subsequent advancements have extended these foundational methods (logits and direct scoring) by incorporating more structured prompting techniques and optimization methods, thereby improving the reliability and consistency of LLM-based evaluation.
This has led to three major kinds of evaluation techniques: Single-input evaluation, where the model’s response is judged individually. Win-rate evaluation, where the model’s response is compared against another response, and accuracy is calculated based on how many times the desired response performs better than the reference. This is useful for comparative studies between different models to determine how often one model outperforms another. Ranking-based evaluation, where multiple responses are ranked either together or across different inferences—an extension of the pointwise approach.
| TYPE | HOW ARE RESPONSES JUDGED? | WHAT IS OUTPUT? |
| Single Input Evaluation | Response judged individually. | Scalar reward as output. |
| Win Rate Evaluation | Choosing a better response between many. | Winning or losing of responses as output. |
| Ranking Based Evaluation | Rating and ranking responses for various downstream tasks. | Scalar reward as well as rank as output. |
Caution: However there are some limitations to use LLMs as a Judge as shown in the paper Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. These include positional bias when evaluating multiple responses together, favoring longer, more verbose answers, and a tendency to rate its own generated responses more highly.
Improving Evaluator#
Most existing "LLM-as-a-judge" techniques rely on API access to proprietary language models. However, certain applications may demand more specialized evaluation capabilities, necessitating methods to either enhance the inherent evaluative performance of the model or efficiently adapt it to task-specific requirements. A notable contribution in this area is Prometheus, along with its subsequent extensions into the vision domain.
Prometheus contributed a publicly available dataset specifically designed to fine-tune models for improved performance on evaluation tasks. This dataset comprises over 100,000 instruction-response pairs, accompanied by approximately 1,000 scoring rubrics or diverse evaluation strategies. A key achievement of Prometheus was demonstrating a high correlation with GPT-4 evaluations using a model with only 13 billion parameters. Building on this approach, Prometheus Vision extended the methodology to vision-language models (VLMs), enabling similar evaluation capabilities in multimodal settings.
Self Improving Judges#
An emerging direction in this field involves leveraging the "LLM-as-a-judge" framework to enable self-improvement of language models without relying on external reward models typically used in post-training methods such as Proximal Policy Optimization (PPO). Notable contributions in this area include Meta-Rewarding Language Models and Self-Rewarding Language Models, both proposed by Meta.
A common pattern across these works is the use of the language model itself to generate N candidate responses for a given prompt, followed by self-generated evaluations or scores for each response. These evaluations then serve as supervisory signals for post-training. For instance, Self-Rewarding Language Models employ a method where the model generates multiple responses, rates them, and constructs a preference dataset using the highest- and lowest-rated responses. This dataset is subsequently used for Direct Preference Optimization (DPO), enabling reward-free reinforcement learning tuning.
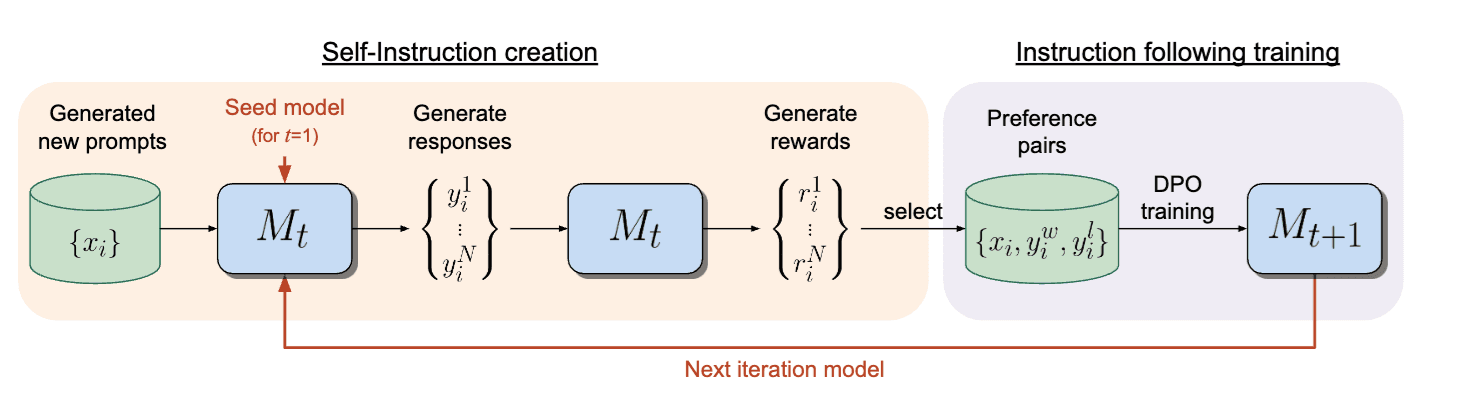
Caution: This approach has a few drawbacks, which may lead to issues with the final model. For example, the model was inherently biased toward unsafe outputs in some cases, so training it based on its self-scored responses could result in an even more biased model overall.
LLM as a Judge at Inference Time#
It is well established that inference-time scaling ie. allocating additional compute during testing can significantly enhance the quality of a model’s final output. A commonly adopted framework involves generating multiple candidate responses from the model and employing an external evaluator to score these outputs. Such evaluators may include programmed heuristics, learned reward models, or external language models acting as judges.
However, LLMs often struggle to fully evaluate reasoning in coding and math tasks. To address this, MCTS-Judge breaks down complex evaluations into simpler steps. It follows standard MCTS stages - selection, expansion, simulation, and backpropagation guided by both global rollout results and local LLM-based assessments. A key feature is its reward mechanism: it uses LLMs to generate and validate test cases, then simulates code execution line-by-line to provide unit-test-level feedback for more accurate judgment.
This paradigm also carries important implications for safety. Employing an LLM as a judge can function as a guardrail mechanism, screening user queries and model outputs to prevent the generation of undesirable or harmful responses. Furthermore, it provides a layer of defense against red teaming attacks by identifying and mitigating unsafe or adversarial behaviors in real time.
Conclusion#
Large-language-model judges are not a futuristic curiosity any more; they’re quickly becoming the go-to yard-stick whenever human evals are too slow or expensive. Three big lessons stand out from the current wave of research:
- They’re surprisingly aligned with humans - typically matching human-human agreement levels in open-ended tasks, which makes them a reliable first pass for many practical workflows.
- They inherit human blind spots - verbosity bias, position bias, and the temptation to inflate their own scores still creep in, so mitigation (randomized answer order, hidden model IDs, explicit rubrics) is non-negotiable.
- They unlock new training loops - from self-rewarding fine-tuning tricks to Monte-Carlo search–style inference, LLM-as-a-Judge is morphing from a static metric into an active component of the modelling stack.
Looking ahead, the real impact will come from domain-specific, open-weight judges (à la Prometheus) that can be audited and improved by the community.
Concerned about AI security? Repello AI specializes in identifying critical vulnerabilities in advanced AI systems before they become costly problems. Our expertise helps prevent the financial losses, legal complications, and reputation damage that come from unsecured AI. Whether you're using conversational assistants, recommendation engines, or automated decision systems, unknown security gaps could be putting your organization at risk.
Book a free consultation with our security experts to discover and address hidden threats in your AI infrastructure.


