
AI that is being built and adopted in enterprises is not a single system. It is an ecosystem that changes every day. The easiest way to lose control of that ecosystem is to not know what exists. Shadow AI, rapid iteration, and agentic workflows create estates that traditional asset discovery and risk profiling miss. In a large enterprise, the spread is wide and uneven. The only durable fix is a live inventory of all AI assets, kept current by automation and tied to risk, owners, and controls.
What “AI asset” really means#
When security teams hear “asset,” they often think of servers or containers. In AI/ML, the surface is wider and more diverse.
- Models: Foundation and fine-tuned models, model checkpoints, and embeddings must be tracked as distinct, versioned artifacts.
- Data: Training and evaluation datasets, RAG knowledge bases, and vector stores require clear classification and governance.
- Logic: System and user prompts, safety guardrails, and policy artifacts define model behavior and must be inventorised as code.
- Runtime: Inference endpoints, agents, tools and plugins, and orchestration layers form the live execution surface that attackers target.
- Supply chain: Notebooks, pipelines, libraries and frameworks, and model cards with metadata form the AI supply chain and deserve the same scrutiny as software dependencies.
- Access: API keys, OAuth configurations, and service identities control powerful capabilities and must be scoped and rotated.
- Observability: Usage and prompt logs, audit trails, and security events provide accountability and should be retained with appropriate controls.
Managing only the model is like locking the front door and leaving the windows open. Any item above can become an entry point if it is handled poorly.
Every CISO should know the answer to : *“What AI systems do we have, where are they, and how do they connect?”*Building a method to see these assets, wherever they reside in the organisation, is complex and challenging work - but it is essential.
Thus, to lay the groundwork for AI-SPM in the age of GenAI, we propose a framework that security teams can use to benchmark and evaluate AI-SPM tools and services. We call this VANTAGE.
The VANTAGE framework for AI-SPM#
VANTAGE outlines the building blocks for discovering and governing various kinds of AI assets across code, cloud, and third-party services. It gives security leaders a clear checklist to evaluate tools and processes.
1) Visibility: make discovery continuous, not quarterly#
Goal: The enterprise must see both managed and unmanaged AI wherever it runs.
How it shows up in practice (examples):
- Code and repositories: Flagging
.ipynb,.safetensors,.bin, ONNX files, prompt files, and model configurations in GitHub or Bitbucket, and it surfaces model weights stored in object storage. - Cloud and data: The team enumerates inference endpoints, indexes vector databases such as Pinecone or Weaviate by collection and namespace, and identifies public or misconfigured buckets that hold training data.
- SaaS and third-party services: Discovery API usage to LLM providers and lists agent builders and plugins that are connected to internal applications.
- Signals and telemetry: CI/CD logs, cloud tags, and runtime telemetry (http, proxy,eBPF) are mined to infer “hidden” assets that were never registered.
Outcome: The organisation maintains a living AI bill of materials (AI-BOM) that updates automatically as engineers ship changes.
2) Accountability: attach owners, purpose, and data classes#
Goal: Every asset must have a responsible person and a clearly defined reason to exist.
What to capture (examples):
- Ownership: Each asset lists a business owner, a technical steward, and an on-call group for escalation.
- Purpose and scope: Each asset records the use case, the environment (development, test, production), the tenant, and the region.
- Data classes: Each asset declares relevant data categories such as PII, PHI, or PCI, the applicable retention policy, and the lawful basis where required.
- Lifecycle: Each asset carries a lifecycle status (experimental, pilot, production), a planned sunset date, and a review cadence.
Outcome: The programme eliminates orphaned prompts, endpoints, and datasets, accelerates approvals, and reduces operational surprises.
3) Normalise: one schema, end-to-end lineage#
Goal: The organisation uses a single way to describe AI assets and to map how they connect.
This can be done by classifying assets identified in the visibility steps into artifacts (e.g. data artifact, model artifact, agent artifact) and then using a graph db to establish connections between various artifacts.
What “good” looks like (examples):
- Canonical schema: The catalogue stores artifact type, version, location, identities, applied controls, and the current risk score for the asset in a single schema.
- Lineage graph: The inventory models clear relationships such as
dataset → training job → model version → vector store → application or agent → endpoint. - Traceability: Analysts can navigate from a production output back to the datasets, parameters, and prompts that influenced it.
Outcome: Teams can trace back vulnerabilities and incidents in minutes rather than weeks.
4) Threat and risk scoring: red-team and assess like it is AI#
Goal: Enterprises should get red-teaming assessments done for GenAI apps like ai agents as they have high agency and can lead to critical vulnerabilities. In addition to this comprehensive risk assessments of other ai assets should be done through code, data and model scanning.
Practical lenses (examples):
- Prompt exposure: The assessment determines whether system prompts can be extracted and whether outputs are protected by guardrails.
- Data-poisoning paths: The assessment verifies whether external sources can write into training pipelines or RAG corpora.
- Model abuse and extraction: The assessment identifies open endpoints, weak rate limits, missing authentication, and gaps in model cards or documentation.
- Excessive agency and permissions: The assessment detects agents with broad IAM scopes and plugins that can call sensitive systems without controls.
- Drift and impact: The assessment measures behavioural changes on protected queries and identifies hallucinations on high-risk tasks.
Automated red-teaming for GenAI applications (for example with Repello's ARTEMIS) helps surface exploitable issues in chatbots, agents, and copilots. These exercises should be paired with model and code scanners to provide depth. Teams should fix exploitable issues first.
Outcome: Security leaders receive clear, business-relevant risk signals that drive focused remediation.
5) Apply controls: apply controls to deal with agency risks#
Goal: Organisations need to apply controls to reduce blast radius without slowing builders. Controls turn policy into enforcement at the points of highest leverage : identity, inputs/outputs, artifacts, and pipelines. Role- and attribute-based access control (RBAC/ABAC) keep privileges narrow and time-bound so agents and services cannot laterally move or escalate.
Controls that work (examples):
- Least privilege by default: Teams right-size identities for models and agents, scope secrets per environment, and eliminate blanket access to data lakes.
- Input and output safety: User-facing flows enforce input validation and output filtering, and sensitive tool calls are disallowed from untrusted prompts.
- Artifact protection: Model weights and logs are encrypted; checkpoints carry integrity checks; storage and rotation follow policy.
- Shift-left gates: CI/CD and MLOps checks enforce policy as code so unsafe prompts, datasets, and endpoints do not reach production.
Outcome: Releases become safer and emergency rollbacks become less frequent.
6) Guard and monitor: watch posture and behaviour#
Goal: Runtime security should be implemented for AI apps in production consisting of guardrails and real-time monitoring.
Safety guardrails on prompts and outputs prevent both security failures (such as injection and data leakage) and safety failures (such as harmful or non-compliant content).
Tracing of agent calls, model calls, tool calls, interactions with databases and knowledge bases gives realtime monitoring of instruction and data flows through the AI pipelines.
Detections to wire in (examples):
- Suspicious access: The system flags spikes to model endpoints, unusual token usage, and privilege escalation by agents.
- Poisoning indicators: The system detects sudden changes in RAG collection composition and identifies externally writable sources that feed training jobs.
- Output anomalies: The system tracks drift on regulated intents and highlights new failure patterns on high-stakes prompts.
- Guardrail tampering: The monitoring stack raises alerts when safety configurations are disabled or loosened.
ARGUS by Repello AI is an end-to-end runtime security platform for applying guardrails across AI agent trust boundaries (between user and agent, between agent and tools etc) and provides live monitoring into data flows across agents, tools, knowledge bases, databases, MCP servers and more.
Outcome: Applications become secure from injection and unwanted leaks and the security team can see the data flowing through each trust boundary.
7) Evolve: review, retire, and reduce waste#
Goal: Enterprises should keep the estate of AI assets lean, current, and defensible.
Routines that pay off (examples):
- Quarterly culls: The team retires inactive models, stale vector indexes, and test endpoints, and it reclaims exposed or unused keys.
- Owner attestations: Asset owners periodically re-confirm purpose, data classes, and controls, and the system automatically freezes assets that lack attestation.
- Cost and risk tie-off: The team reports the dollars saved and the risk points removed by decommissioning efforts.
Outcome: The organisation reduces attack surface, lowers spend, and improves the signal-to-noise ratio in monitoring.
How do you solve for Visibility and Inventorization at scale?#
To build your AI security posture on the VANTAGE framework, having a wide coverage is necessary, so that it covers all sorts of AI assets in the organisation. Here we propose a sample architecture for achieving this goal.
The existence of AI assets in organizations can be categorised into 4 classes :
- Code Repositories : Github, Gitlab, BitBucket and more
- Cloud : AWS Sagemaker, Bedrock, s3 buckets, Azure Devops, Google Cloud’s Vertex AI and more
- Infra and Applications : On-prem servers, Kubernetes clusters, Inference endpoints, AI microservices and more
- 3rd party Integrations : OpenAI, Claude, Gemini APIs and more
Henceforth, let us refer to these classes as sources.
The proposed architecture is based on a multi-tier modular approach consisting of the following components :
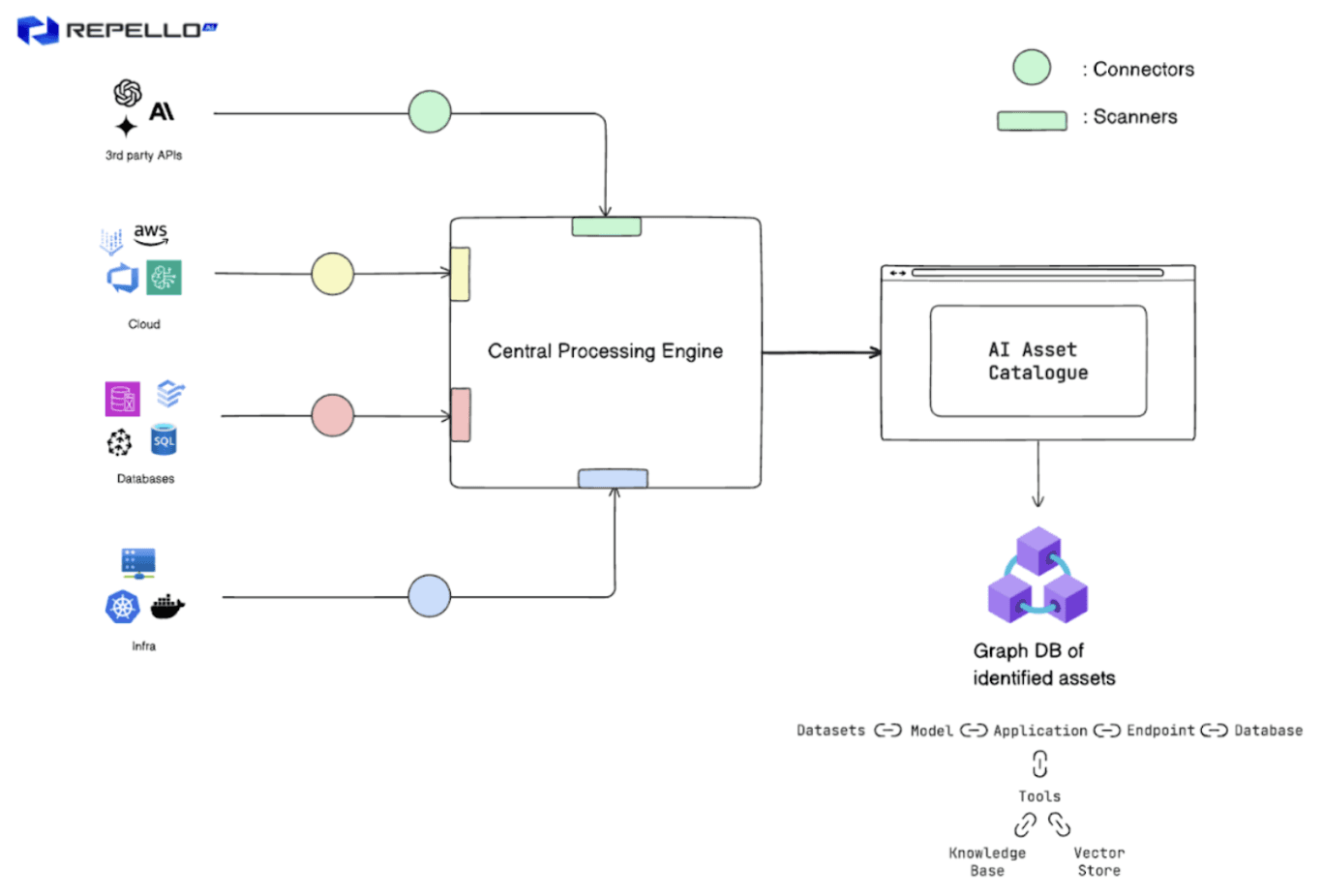
Fig: Architecture Schema
-
Discovery Connectors : These are elements that connect github repositories, cloud platforms, on-prem servers and other sources with the CPE (Central Processing Engine) for identification. Think of them as interfaces that act as the link between the sources and the CPE. There can be multiple different kinds of connectors based on the sources they connect to. For example connectors for Github, Gitlab, AWS Sagemaker, Azure Devops and more.
Each connector should allow the CPE to scan data either continuously or on a schedule.
-
Central Processing Engine : This is the core engine for scanning the sources identifying AI assets. The CPE uses various techniques - some generic, like pattern matching, ML model based classification, rule based engine; and some specific to the source, to enumerate different assets across code, cloud, infra and 3rd party services.
Some examples of identification methodology of AI assets across different sources can be as follows :
-
Code Repo scanning :
- Search for frameworks like tensorflow, pythorch, sklearn, transformers in the code.
- Refer to model files .pt, .pkl, .onnx.
- Look for API key usage like OPENAI_API_KEY, CLAUDE_API_KEY.
-
Cloud Scanning :
- Endpoints in AWS Sagemaker or Bedrock
- Managed models (available in services like Bedrock) v/s unmanaged models (hosted independently on Huggingface)
- Datasets in S3 buckets, RedShift identified by naming or static rules.
-
The other task of the CPE is to categorise the identified AI Assets into artifacts. Artifacts can be thought of as nothing but classes of different kinds of assets for e.g : model artifacts, endpoint artifacts, dataset artifacts and more.
-
Central Asset Catalogue and Relationship Mapping : Once the data has been processed by CPE it has to be cataloged. The inventory thus created can be fed to a graph db to establish connections and network to fulfill the ‘Normalise’ section of the VANTAGE framework. Individual assets can be stored with some metadata consisting of artifact type, name, location, tags, last seen and timestamp.
Catalogue can be updated automatically when new addition or change occurs i.e., it can be event-driven or scheduled.
This architecture poses a robust inventorization mechanism with scalability, wide coverage and real-time updates. Repello AI customers are already using this in their enterprise for AI asset discovery across multiple sources. Our robust connector network provides a wide coverage. Once the assets are identified our automated red-teaming solution ARTEMIS and runtime security solution ARGUS can be used to provide complete protection across your organisation’s AI posture.
Metrics that matter#
- The percentage of AI assets with confirmed owner and purpose reflects the strength of governance
- The mean time from discovery to owner assignment indicates how quickly blind spots are closed.
- The percentage of production AI applications with complete lineage to training and inference data shows audit readiness.
- The percentage of endpoints with guardrails and RBAC enforced demonstrates control coverage.
- The time to remediate AI-specific high-risk findings (injection, poisoning, excessive agency) measures operational effectiveness.
- The number of inactive AI artifacts removed per quarter (models and vector indexes) indicates progress in hygiene and cost control.
Common pitfalls#
- Model-only thinking: Teams that inventory only models miss real attack paths; a complete inventory must include prompts, data, endpoints, agents, credentials, and logs.
- Point-in-time audits: Because AI changes hourly, discovery must be continuous to stay accurate.
- Siloed security: AI posture must integrate with existing SOC and incident response so detections and response are unified.
- Letting inactive assets linger: Regular retirement and key reclamation reduce both cost and risk.
Even as laws evolve, auditors already expect traceability regarding what trained a model, documentation of purpose and limitations, and controls mapped to AI-specific risks. A live inventory with lineage produces that evidence quickly. Discovery, paired with AISPM-style practices, achieves this without stalling delivery.
Takeaway#
AI security fails when visibility fails. The core message of this piece is simple: you cannot manage posture without a live, automated inventory of all AI assets - models, prompts, datasets, vector stores, agents, endpoints, keys, and the pipelines that connect them.
VANTAGE turns that inventory into an operating model: make discovery continuous, assign clear ownership, standardise schema and lineage, assess AI-specific risk, enforce controls where they matter, monitor behaviour in real time, and retire what you do not need. Do this well and you cut blind spots, reduce incidents, speed up audits, and lower spend.
This is hard to execute by hand. It requires broad connectors, smart classification, a reliable catalogue and graph, policy gates in CI/CD, and runtime detections that understand AI systems—not just servers. That is where Repello AI is relevant. Our platform gives you wide inventorisation coverage across code, cloud, infra, and third-party services. ARTEMIS delivers automated red-teaming for GenAI apps and agents, turning theoretical risks into concrete, exploitable findings you can fix. ARGUS adds runtime guardrails and live tracing across agent trust boundaries so you can see and stop injection, data leakage, and unsafe tool use before they become incidents.
If you want VANTAGE in production let us show you how teams are doing it today.
Book a demo now, and we will walk you through inventorisation at scale, targeted red-teaming, and runtime protection that plugs straight into your existing workflows.


