
Introduction#
Speech-to-Text (STT) systems are increasingly integral to virtual assistants, transcription services, and voice-controlled applications. However, they are vulnerable to adversarial attacks which are subtle, intentionally crafted perturbations to audio that are imperceptible to humans leading to targeted errors in transcriptions. We explore adversarial audio generation techniques targeting two state-of-the-art STT models: OpenAI’s Whisper and Wav2Vec2 from Meta AI.
Attack Space: Where Vulnerabilities Arise#
The attack space in STT models lies in their end-to-end differentiability and their dependency on high-dimensional input representations (e.g., raw waveforms or spectrograms). These models are sensitive to slight perturbations in the audio signal, which adversaries can exploit to:
- Mislead the transcription output
- Suppress or inject specific target phrases
- Undermine the integrity of ASR (Automatic Speech Recognition) pipelines
Untargeted vs Targeted Attacks#
Untargeted Attacks simply aim to produce any incorrect output from the STT model, misleading the output from its correct output. The goal is to decrease transcription accuracy, which is often easier.
Targeted Attacks force the model to transcribe the audio into a specific attacker-chosen phrase.They require aligning the audio and target text in a semantically plausible way. These kinds of attacks are slightly difficult to produce compared to non-targeted attacks, especially for autoregressive models like Whisper, as decoding depends on previous tokens.
Advanced adversarial attack algorithms are highly effective at performing targeted attacks because they either exploit precise gradients or often rely on techniques which iteratively modify inputs based on model outputs (logits or confidence scores) to subtly manipulate inputs in ways that steer model predictions toward specific, attacker-chosen outputs without altering human perception. With careful selection of the attack algorithm driving the alignment of the audio outputs from the model and the target text, successful adversarial perturbations can be crafted to fool the system’s outputs.
Models Under Attack#
We tested the attack strategy on two classes of models. These two classes of models significantly differ from each other in various aspects including but not limited to architecture, input representation, loss functions etc.
Meta’s Wav2Vec2 is a non-autoregressive model, specifically trained on raw audio waveforms on the Connectionist Temporal Classification (CTC) loss. Mainly designed as an encoder, it transforms raw audio into a sequence of latent speech representations by first processing the audio with a convolutional layer, followed by a transformer encoder. In these cases, the decoder doesn't generate tokens sequentially, but instead outputs a probability distribution over all possible tokens simultaneously.
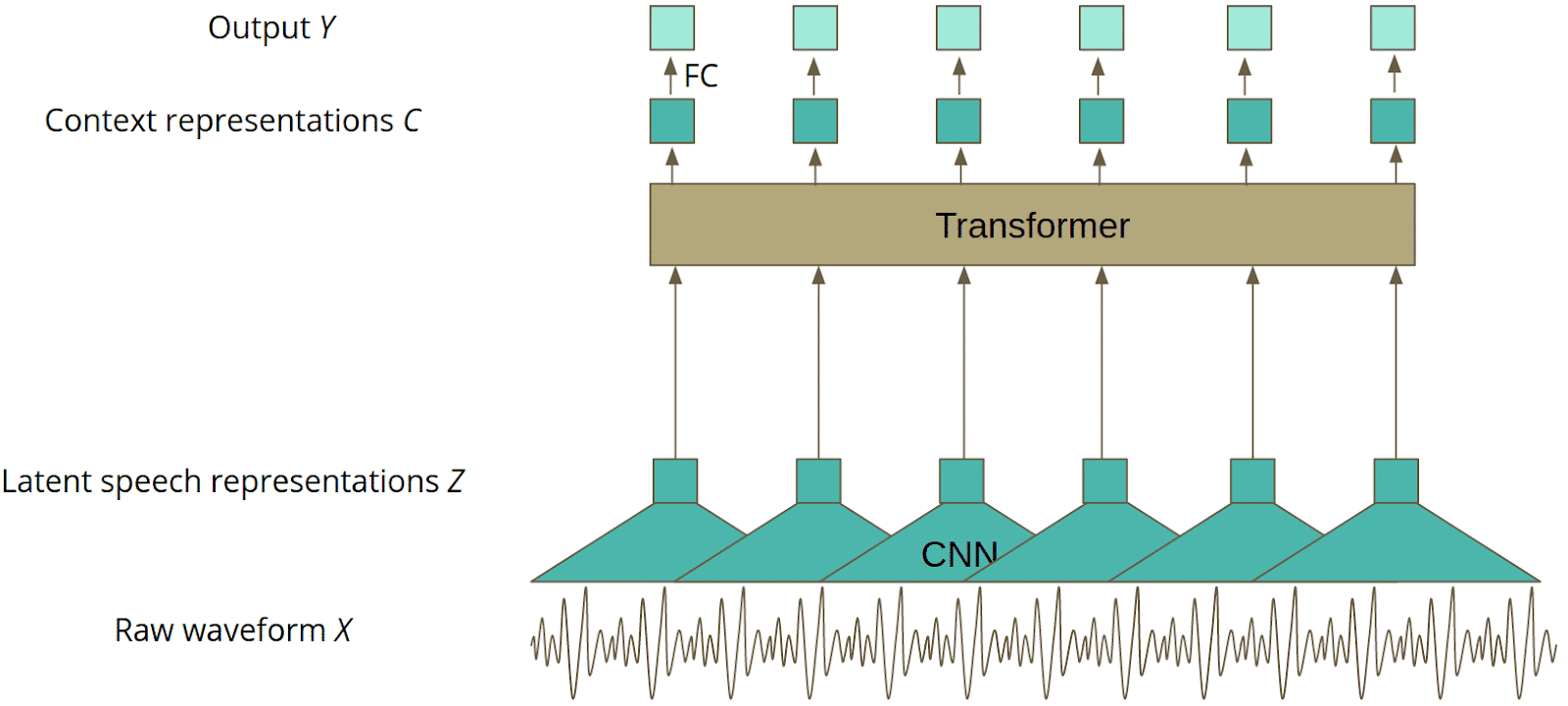
Fine-tuned Wav2Vec 2.0 model architecture [Source]
OpenAI’s Whisper is an autoregressive Seq2Seq model having an encoder-decoder transformer architecture. The model is trained on Mel-Spectrograms of the raw waveforms with a Cross-Entropy loss, fully equipped to handle the tasks of translation and transcription. Since the model is multi-task and multi-lingual, the WhisperTokenizer has special prefix tokens to define the scope of the output that sets the language and task of the output.
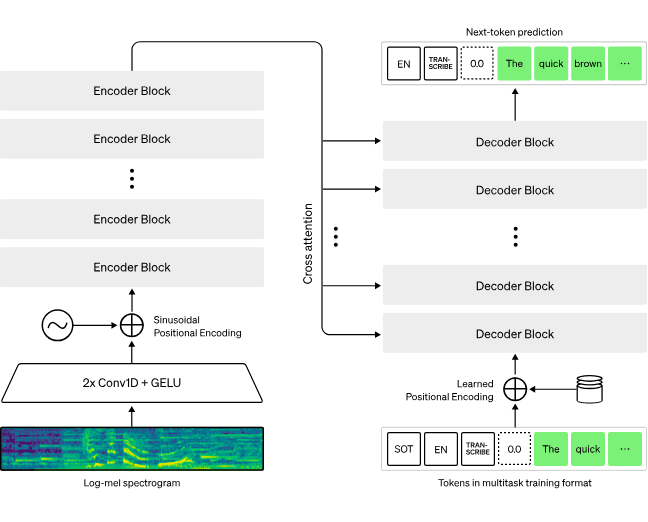
Whisper’s Encoder-Decoder Transformer Architecture [Source]
Generating Adversarial Examples#
We used the Basic Iterative Method (BIM) for audio adversarial generation. The BIM is an extension of Fast Gradient Sign Method (FGSM), is a powerful technique used in the field of adversarial machine learning, particularly for generating adversarial examples.
Key features of the BIM algorithm are:
- Instead of making a single large update to the input, BIM makes smaller updates iteratively, controllable by a hyperparameter. This allows for more controlled and effective manipulation of the audio signal, increasing the likelihood of successfully deceiving the model.
- To ensure that the perturbations remain imperceptible to human listeners, BIM constrains the perturbation within an L-infinity bound, keeping the generated adversarial audio similar to the original audio, making it harder to detect.
- During each iteration, BIM computes a loss function that quantifies how well the perturbed audio performs against the target label. The model's gradients are then calculated with respect to this loss, allowing BIM to determine the direction in which to adjust the audio for a targeted attack.
An additional L2 penalty between the original audio and the generated adversarial audio is added to the loss function of Meta’s wav2vec2 model before the gradient computation. This is done to ensure the quality of the generated waveform doesn’t degrade too much in comparison to the original audio waveform.
One effective approach for generating adversarial audio against models like Whisper, which operate on spectrogram representations (e.g., log-Mel spectrograms), is to implement a fully differentiable waveform-to-spectrogram feature extractor using a package like PyTorch having an autograd system. This enables backpropagation of gradients from the model’s output all the way to the raw audio waveform. In our implementation, adversarial perturbations are applied directly to the waveform by leveraging this differentiable feature extractor, allowing gradient flow from spectrograms to the raw waveforms, enabling end-to-end optimization for gradient-based methods such as PGD, FGSM, BIM and more. See the GitHub implementation of the Differentiable Feature Extractor for more details.
An interactive demonstration is available at the Attack Audio Generation Playground.
Check out the Demo playground in Google Colab.
Defending against Adversarial Audio Attacks#
To mitigate these risks, it is crucial to implement robust defenses against adversarial attacks. Some effective strategies include:
- Adversarial Training: Incorporating adversarial examples into the training dataset can help models learn to recognize and resist such perturbations, enhancing their robustness.
- Input Preprocessing: Implementing preprocessing techniques to either filter out potential adversarial noise that can help in maintaining the integrity of the input audio or changing the noise distribution .
- Ensemble Methods: Using multiple models and aggregating their predictions can reduce the likelihood of a single adversarial example successfully deceiving the system.
- Input and Output Guardrail Validation: Having an input and output validation system after each module to filter out any kind of malicious, harmful or offensive instruction/output before reaching the next module/user of the system
Conclusion and Future Directions#
Audio Adversarial Attacks can lead to misinterpretations of spoken language, resulting in erroneous transcriptions that may have serious implications in various applications, such as voice-activated assistants, transcription services, and security systems which can easily lead to compromising security protocols or spreading misinformation. For instance, adversarial examples could be crafted to manipulate the output of a voice-controlled system, leading to unauthorized actions or access. The implications of such adversarial attacks highlight the need for ongoing research and development in the field of audio processing and machine learning.
Looking ahead, future directions for this work could include:
- Developing Robust Defense Mechanisms: Focusing on creating more sophisticated defenses that can adapt to evolving adversarial strategies.
- Real-World Testing: Conducting experiments in real-world environments (In-The-Air transmission) to assess the effectiveness of both adversarial attacks and defense mechanisms, providing valuable data for improving model robustness.
- Cross-Modal Attacks: Examining how adversarial techniques can be applied across different modalities, such as combining audio with visual inputs, to create more complex and challenging adversarial scenarios.
By continuing to investigate these areas, we can contribute to the development of more secure and reliable STT models and ASR systems, ultimately enhancing user trust and safety in voice-reliant systems.
Concerned about AI security? Repello AI specializes in identifying critical vulnerabilities in advanced AI systems before they become costly problems. Our expertise helps prevent the financial losses, legal complications, and reputation damage that come from unsecured AI. Whether you're using conversational assistants, recommendation engines, or automated decision systems, unknown security gaps could be putting your organization at risk.
Book a free consultation with our security experts to discover and address hidden threats in your AI infrastructure.


