

Diffusion models are a class of generative models capable of generating novel images that were not part of the training data. Modern-day diffusion models can produce intricately detailed images and scenes from just a prompt (T2I), and can even edit existing images based on a prompt. Despite these advancements, the fundamental backbone of these generative models remains the same - they are trained on a large corpora of data, learning to generate samples that fall within the learned distribution, which, in the case of diffusion models, typically consists of images or text-image pairs. This data is usually scraped from the internet and is not always safe, which can lead to the model generating unsafe content that was present in the training set.
In this blog, we will first dive into the core mechanics of diffusion models—the “Diffusion and Reverse Diffusion Process.” We will explore how modern diffusion models generate images conditioned on textual prompts, and how this architecture can be exploited to guide a model into generating unsafe or NSFW content.
Generative Models v/s Diffusion Models#
Generative models are a class of models that learn the underlying data distribution in order to generate new samples that resemble the training data. Suppose the true data distribution is pdata(x), and the model learns a distribution pθ(x). The goal of the generative model is to essentially minimize the divergence between these two distributions.
In the context of image generation, several types of generative models have been developed, including VAEs, GANs, and Flow-based models. Variational Autoencoders (VAEs) learn a probabilistic latent space but often generate blurry images due to their reliance on a simple Gaussian prior. Generative Adversarial Networks (GANs) produce sharp and realistic images but are notoriously difficult to train. They suffer from issues like mode collapse (producing limited diversity) and instability due to adversarial training dynamics. Flow-based models (e.g., RealNVP, Glow) allow exact likelihood computation and latent-variable inference but require complex, invertible architectures and often struggle with modeling high-resolution images efficiently.
Diffusion models, on the other hand, offer a more stable and scalable alternative. They work by gradually adding noise to the data and then learning to reverse this process step-by-step. This allows for high-quality, diverse image generation without adversarial training. Diffusion models have shown strong performance on a range of generative tasks and avoid many of the pitfalls of earlier approaches.
Working of Vanilla Diffusion Models#
Forward Diffusion Process:#
Starting with the original data point, say an image x₀, Gaussian noise is added to the image at each step, gradually making it noisier. As t→infinity, the result becomes pure Gaussian noise. This addition of noise is controlled by a variable βₜ, which changes over time and is usually linearly scheduled. This means that more noise is added at later time steps—when the image is already noisy—while in the beginning, noise is added more slowly to avoid completely destroying the image within just a few steps.
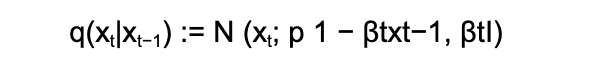
Reverse Diffusion Process:#
The reverse process involves estimating xₜ₋₁ given xₜ, which is a slightly denoised version of the noisy image at time t. This process would require access to the entire data distribution, which is generally not available or feasible. Hence, we train a neural network—typically a U-Net or in modern diffusion models, a DiT (Diffusion Transformer)—to estimate xₜ₋₁ given xₜ. This U-Net can be used to predict the noise present in the image at each time step, which can then be subtracted from the noisy image to obtain a denoised version. In this way training the denoising model on enough images the model learns to generate novel samples from just the Gaussian distribution.
In present day diffusion models these stages at each time stamp time can be further replaced by a latent distribution i.e. the forward and backward diffusion process takes place not in a pixel space but a latent space. An auto encoder model can be then used to first compress the image to latent space and a decoder to project the image back to pixel space.
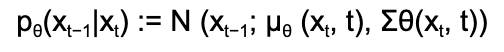

Unsafe Generation in Diffusion Models#
Before diving into how diffusion models can generate unsafe content, we first need to define what "unsafe" means in this context. This includes sexually explicit content, violent content, disturbing imagery, hateful content, or politically sensitive material. There are a number of ways attackers can prompt or manipulate models to produce such outputs, we will explore how these attack methods exploit the model's architecture to force it to generate unsafe content. As per the paper [https://arxiv.org/pdf/2408.03400], there are three major types of attacks on diffusion models: Adversarial Attacks, Membership Inference Attacks (MIA), and Backdoor Attacks, which are discussed below. For each type, a method used to perform the attack is also described.
Adversarial Attacks#
In these kinds of attack an adversarial prompt/input disguised as safe can be used to breach models security and used to generate unsafe content.
Text-based prompt manipulation is less effective, as it can easily be mitigated by text filters. These attacks work by altering the input text in ways that preserve the malicious intent while evading detection mechanisms. One major approach adopted here is to find token sequences that are close to NSFW concepts in embedding space and inserting them into benign tokens.
A more concerning development is the emergence of image-based adversarial attacks used in image-to-image translation tasks. Unlike text-based approaches that can be detected through pattern analysis, image attacks manipulate the actual input images to guide diffusion models toward generating unsafe content.
In this we will particularly discuss in detail about the method adopted in the paper ADVI2I in detail. The AdvI2I algorithm introduces an adversarial image attack on image-to-image diffusion models by leveraging harmful prompt concepts to subtly manipulate image generation. It begins with a clean image set, a set of regular text prompts, and pairs of NSFW prompts, one harmful and one benign to extract a concept vector that captures the difference in their representations. This concept vector is scaled by a strength coefficient alpha and added to regular prompts to bias the diffusion process.
A separate adversarial noise generator is initialized and trained iteratively. During each training step, a clean image and a prompt are sampled, and a modified prompt feature is created by incorporating the harmful concept. An adversarial version of the image is then generated and constrained to stay visually similar to the original by clamping the noise within a small range.
The model computes the difference between the features of the adversarial and clean images under the modified prompt. If using the adaptive variant, Gaussian noise is added and a safety checker loss is included to penalize safe outputs. The total loss combines this similarity loss and, if applicable, the safety checker penalty, and is used to update the generator. In the inference stage, the trained generator produces adversarial images from clean ones, which are then processed by the diffusion model using benign prompts—potentially leading to harmful or unsafe content.
Examples from paper:

Detailed Algorithm from paper:

Membership inference Attacks#
Membership inference attacks aim to determine whether a given sample was part of a model’s training data. While several MIA techniques exist for image generation models like GANs and VAEs, they cannot be directly applied to diffusion models due to the fundamentally different nature of their architectures. In this discussion, we explore an intuitive approach for detecting membership in diffusion models. The core assumption is simple: samples that were part of the training data tend to have lower generation loss than those that were not. We delve into the details of the paper Are Diffusion Models Vulnerable to Membership Inference Attacks?, which formalizes this idea and proposes effective attack methods.
Diffusion models learn to reverse a noise corruption process over a sequence of steps, typically modeled as a Markov chain. During training, they minimize the difference between the predicted and true posterior means derived from the forward diffusion process.
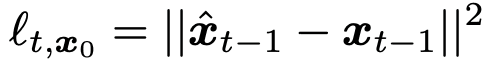
Mathematically, the local estimation error of a single data point at timestep t is computed. Since computing the exact posterior is intractable, the paper proposes using deterministic approximations based on the denoising function and the forward sampling function, leading to an approximate t-error. According to the key assumption, member data points will exhibit lower t-error values compared to non-member points.
Based on this, the paper introduces two attack techniques. The first is a statistical approach, where the t-error at a particular timestep is calculated, and if it falls below a certain threshold, the sample is classified as a member. The second method involves a neural network-based attack, where an attack model takes the pixel-wise absolute value of the estimation error as input and predicts the likelihood of the sample being a member. Both approaches achieve strong membership inference performance, highlighting a key vulnerability in diffusion-based generative models.
Backdoor and Trojan Attacks#
Backdoor attacks insert hidden malicious behavior into a model during training, triggered by specific inputs like image patterns or keywords. The model works normally on regular inputs but behaves wrongly when it sees the trigger. This contrasts with adversarial attacks that don't change the model, they slightly alter the input at test time to fool the model into making mistakes. The key difference is: backdoors are planted during training and rely on hidden triggers, while adversarial attacks happen at inference time through small, crafted perturbations.
In this we will discuss a prominent paper in backdoor attacks in Diffusion models TrojDiff. TrojDiff is a backdoor attack on diffusion models (DDPM/DDIM) where an attacker injects a trigger (e.g., blended image or patch) into the noise input, forcing the model to generate malicious outputs when the trigger is present.
The Trojan noise follows a modified distribution N(μ,γ2I), where μ=(1−γ)δ and δ is the trigger. During training, the model learns both the standard denoising process and a Trojan reverse process, optimized via a noise-prediction loss. At inference, clean noise yields normal outputs, but Trojan noise crafted with the trigger forces targeted outputs, such as an in-distribution class (In-D2D), out-of-distribution content (Out-D2D), or a specific image (D2I). The attack works for both DDPM and DDIM, and supports patch-based triggers by masking noise regions. In the below diagram you can see how having a different initial noise of say hello kitty blended leads to a different generation. Each image is the single time stamp in the diffusion process.

Conclusion#
Diffusion models have rapidly moved from research curiosities to the creative engines behind state-of-the-art image generation, editing, and even video synthesis. Their appeal is obvious: a relatively stable training procedure, unprecedented visual fidelity, and an almost magical ability to follow natural-language prompts. Yet, as we have seen, the same architectural choices that make diffusion models so powerful also leave them surprisingly brittle.
Real defense will require deeper changes across the entire diffusion pipeline:
- Curated, provenance-tracked datasets : to reduce the ingestion of unsafe or copyrighted material in the first place.
- Robust training objectives : for example, adversarially-trained or certified denoisers - that make it harder for small perturbations or hidden triggers to dominate the reverse process.
- Fine-grained interpretability tools : to inspect how textual concepts map onto latent trajectories, flagging suspicious prompt manipulations early.
- Privacy-preserving techniques : (e.g., differential privacy or regularized score matching) to blunt membership inference without tanking image quality.
- Continuous red-team evaluation : that evolves with new attack papers, ensuring that “fixes” are validated against tomorrow’s threats, not just yesterday’s exploits.
Ultimately, diffusion models will keep pushing the frontier of generative AI, but only if we push just as hard on understanding their failure modes. By treating security and safety as first-class research problems, we can enjoy the Ghibli-like dreams these models create without falling prey to the adversarial schemes lurking in their latent space.
Concerned about AI security? Repello AI specializes in identifying critical vulnerabilities in advanced AI systems before they become costly problems. Our expertise helps prevent the financial losses, legal complications, and reputation damage that come from unsecured AI. Whether you're using conversational assistants, recommendation engines, or automated decision systems, unknown security gaps could be putting your organization at risk.
Book a free consultation with our security experts to discover and address hidden threats in your AI infrastructure.
References#
Are Diffusion Models Vulnerable to Membership Inference Attacks?
Denoising Diffusion Probabilistic Models
High-Resolution Image Synthesis with Latent Diffusion Models
AdvI2I: Adversarial Image Attack on Image-to-Image Diffusion models
TrojDiff: Trojan Attacks on Diffusion Models with Diverse Targets


