
Anthropic launched Claude Code Security yesterday — an AI-powered vulnerability scanner that uses Claude Opus 4.6 to find code-level bugs like SQL injection, memory corruption, and authentication bypass. It found 500+ real vulnerabilities in production open-source codebases that human reviewers missed for decades. Cybersecurity stocks dropped on the news. The market misread what was actually launched. Claude Code Security secures your codebase. It doesn't secure your AI applications. Those are different problems, and confusing them leaves a dangerous gap.
What Claude Code Security Actually Does#
Anthropic's announcement is technically precise. Claude Code Security "scans codebases for security vulnerabilities and suggests targeted software patches for human review, allowing teams to find and fix security issues that traditional methods often miss."
The key advance over traditional SAST tools is the reasoning approach. Rule-based static analysis looks for known patterns — a strcpy without a bounds check, an unsanitized user input passed to a SQL query. Claude Code Security reasons about how code components interact and how data flows through a system, which is how it catches subtle, context-dependent vulnerabilities that pattern-matching tools miss.
Using Claude Opus 4.6, Anthropic's own team found over 500 vulnerabilities in production open-source codebases — memory corruption, injection flaws, authentication bypasses, logic errors — bugs that had survived years of expert review. The findings are currently going through responsible disclosure. Anthropic is also using it to scan its own code.
This is genuinely impressive. Code-level reasoning at this scale matters for application security.
Why Cybersecurity Stocks Dropped (and Why That Was the Wrong Reaction)#
CrowdStrike dropped ~8%. Okta fell 9%. Cloudflare dropped ~8%. Palo Alto dipped. The market read "AI can find security vulnerabilities" as a threat to the traditional security tooling industry.
That reaction conflates two different problems.
CrowdStrike detects runtime threats on endpoints. Okta secures identity and access. Cloudflare operates at the network layer. None of them are primarily in the business of scanning application source code for memory corruption bugs. The companies that should worry are SAST vendors — not the broad cybersecurity market.
But there's a deeper confusion embedded in the stock reaction: the assumption that "AI security" means the same thing as "using AI for traditional security tasks." It doesn't. A new category of security problem has emerged — one that Claude Code Security isn't designed to address at all.
The Layer Claude Code Security Doesn't Cover#
Code-level vulnerability scanning answers one question: is this code written securely?
That's the right question for an application that doesn't touch AI. But if your application integrates an LLM — as an API call, a RAG pipeline, an agent with tool access, or an automated decision system — you have a second attack surface that doesn't exist in your code at all. It exists in the behavior of the AI model at runtime.
Consider what Claude Code Security would see if it scanned a production RAG application:
- The API call to your LLM provider: no vulnerability
- The vector database query: no vulnerability
- The document retrieval logic: no vulnerability
- The prompt assembly: no vulnerability
Now consider what an attacker can do to that same application. Inject a malicious document into the retrieval corpus and the model starts leaking data from other users' sessions. Craft a user query that breaks out of the system prompt and accesses restricted functionality. Feed the agent a tool result that hijacks its action sequence. None of these vulnerabilities exist as lines of code. They exist in how the AI processes inputs — which is a runtime, behavioral problem.
Claude Code Security is not built to find these. It's not a limitation or a criticism — it's a scope statement. Code scanning and AI application security test different things.
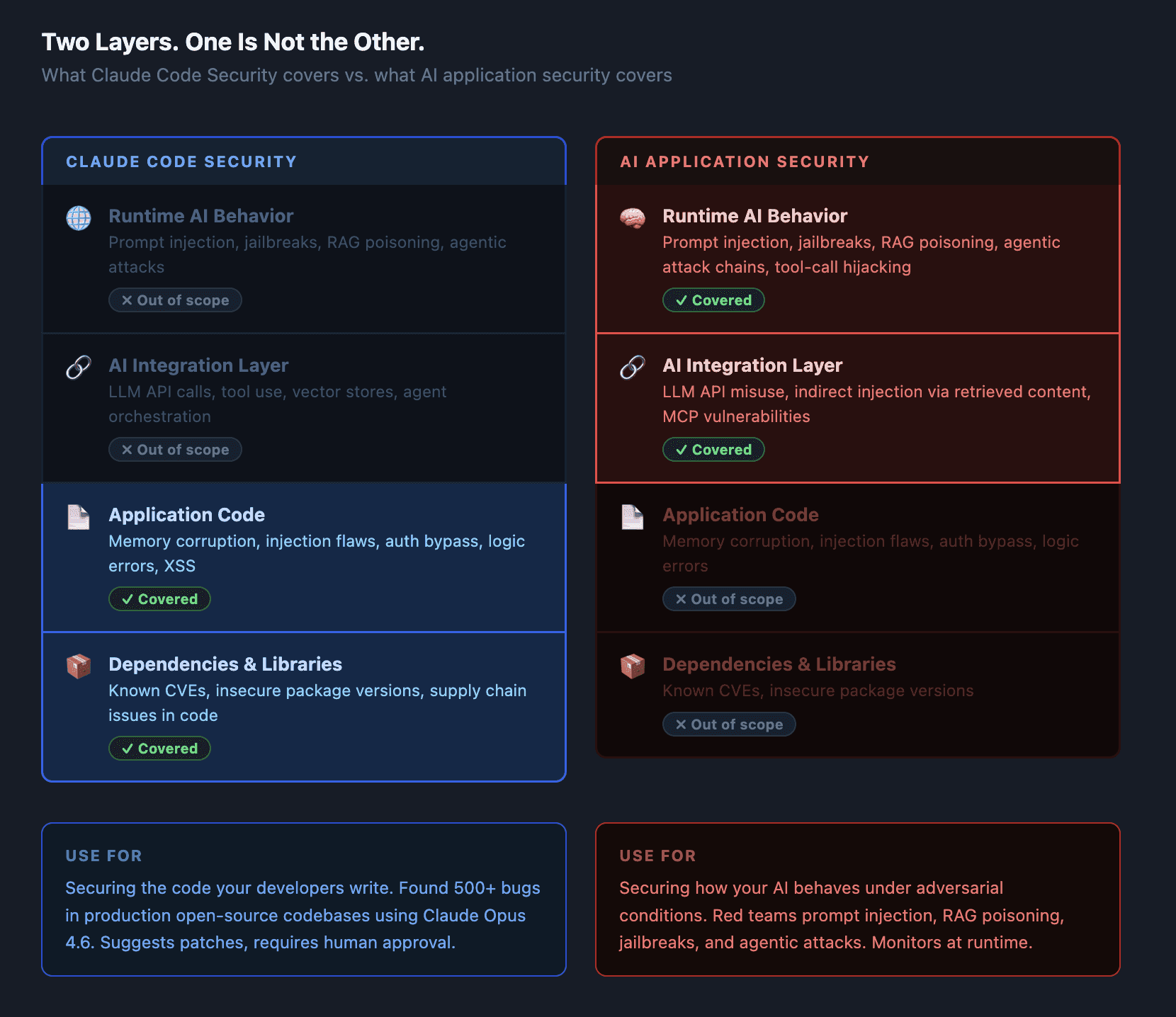
The Four Vulnerability Classes Code Scanning Misses#
Prompt injection — the OWASP LLM Top 10's most critical risk. Attacker-controlled content in the model's context window causes it to override developer instructions. This doesn't appear anywhere in a codebase scan because the vulnerability is in the model's response to input, not in the code that passes the input. Real-world examples range from simple instruction overrides to indirect injection through documents and web content.
RAG poisoning — an attacker plants malicious content in a retrieval corpus, which gets surfaced to the model and shapes its outputs. The retrieval pipeline is code; the poisoning is data. A code scanner sees clean code. The attack succeeds anyway.
Jailbreaking and alignment bypass — systematic techniques to make a model produce outputs its safety training was designed to prevent. Many-shot jailbreaking, multi-turn escalation, token encoding attacks — none of these leave traces in your codebase. They are exploits against the model's trained behavior, not against your code. Automated red teaming is the only way to discover these before an attacker does.
Agentic attack chains — when AI agents can browse the web, call external APIs, execute code, or chain tool calls, the attack surface multiplies. Compromising one tool call can cascade into unauthorized actions across systems. MCP tool poisoning, C2 channels through AI assistants, cross-agent injection — these are runtime attacks in a multi-agent topology. They don't map to any vulnerability class that code scanning covers.
What This Means for Your Security Stack#
Claude Code Security adds real value to the application security layer. If you're writing code — and especially if you're writing code that handles sensitive data, authentication, or external input — having an AI reason over your codebase for subtle logic flaws is a genuine improvement over rule-based SAST.
But if that codebase calls an LLM, you have a second testing obligation that sits above the code layer entirely.
Pre-deployment: You need adversarial testing against the AI itself — not just the code wrapping it. Does your system prompt hold under jailbreak attempts? Can an attacker use your RAG pipeline as an injection vector? Can tool calls be hijacked? ARTEMIS runs AI-specific red team scenarios across all of these attack classes against your live application, not your source code.
Runtime: Code doesn't change after deployment. AI behavior can be influenced at runtime through every input the model receives. A clean bill of health from a pre-deployment scan doesn't protect against a prompt injection attack that arrives in a user message six months after launch. ARGUS provides runtime interception — monitoring model inputs and outputs in production and blocking attacks as they happen.
The two layers are complementary, not competing. Use Claude Code Security to make sure your code is clean. Use AI-specific red teaming and runtime monitoring to make sure your AI is secure.
FAQ#
What does Claude Code Security do?#
Claude Code Security is a new capability built into Claude Code (web version) that uses Claude Opus 4.6 to scan codebases for security vulnerabilities. It reasons over code to find context-dependent bugs — memory corruption, injection flaws, authentication bypass, logic errors — that traditional pattern-matching SAST tools miss. It suggests patches for human review but doesn't automatically apply fixes. It's currently in limited research preview for Enterprise and Team customers.
Why did cybersecurity stocks drop when Claude Code Security launched?#
Markets reacted to "AI can find security vulnerabilities" as a threat to traditional security vendors. The reaction was largely misdirected — CrowdStrike, Okta, and Cloudflare operate at the endpoint, identity, and network layers, not primarily in source code scanning. The companies with more reason to watch this space are SAST/DAST vendors.
Does Claude Code Security find prompt injection vulnerabilities?#
No. Prompt injection is a runtime behavioral vulnerability — it's about how a model responds to attacker-controlled inputs at inference time, not about how the surrounding code is written. Claude Code Security scans source code for traditional vulnerability classes. Detecting prompt injection requires adversarial testing against the live AI application.
What security testing does an AI application need beyond code scanning?#
An AI application needs adversarial testing at the model layer: prompt injection probing, jailbreak resistance testing, RAG poisoning assessment, agentic attack chain analysis, and tool-call hijacking tests. These test the AI's behavior, not the code quality. Pre-deployment red teaming covers this. Runtime monitoring covers the ongoing exposure once the application is live.
Is Claude Code Security a competitor to AI security platforms like Repello?#
No — they address different layers. Claude Code Security tests whether your code is written securely. AI application security platforms test whether your AI behaves securely. Both are necessary for a production AI deployment; neither substitutes for the other.
Test the AI Layer Your Code Scanner Can't Reach#
Claude Code Security gives you a cleaner codebase. ARTEMIS and ARGUS secure what runs on top of it — the AI layer where prompt injection, RAG poisoning, and agentic attacks actually happen. Get a demo to see what your AI application looks like from an attacker's perspective.


